
La banca tradicional financia de forma directa las facturas entre proveedores y sus clientes, pero para órdenes de pedido, que cronológicamente se sitúan en un paso anterior, no tiene un producto propio y lo salvan con préstamos y especialmente con líneas de crédito. La realidad a día de hoy, gracias al desarrollo tecnológico, es que podemos tener un mayor conocimiento del negocio por medio de EDI y podemos tratar y analizar la información para anticipar mucho antes el riesgo o posibles problemas que puedan surgir con un proveedor, consiguiendo así la trazabilidad que nos permitirá controlar la financiación desde la llegada de la orden de pedido hasta el pago de la factura.
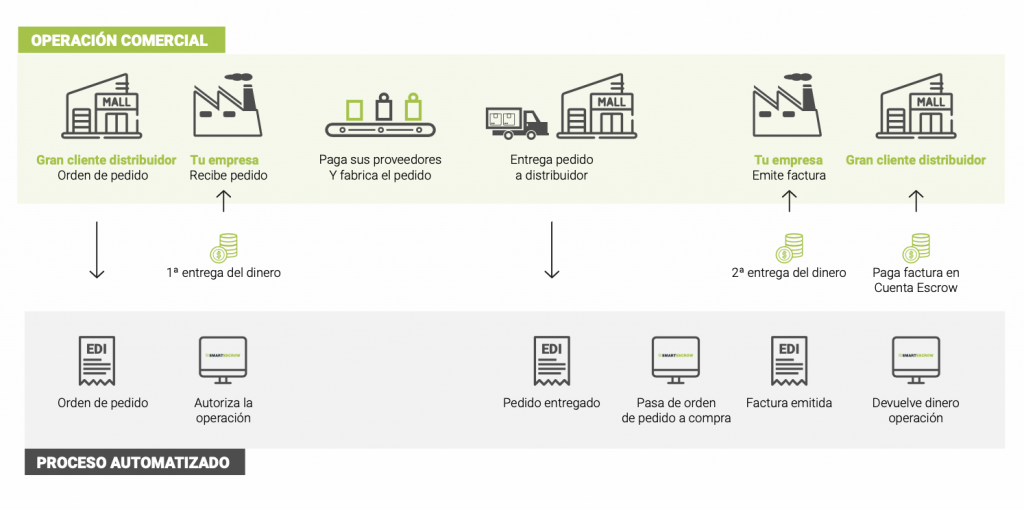
Lanzar un producto basado en la creación de una forma de inversión en deuda distinta a la habitual, que proporcione la posibilidad de financiar el tejido empresarial primario en una de sus primeras fases: el pedido, es posible actuando en los mercados que se rigen por EDI (actualmente todas las grandes marcas trabajan con este sistema y obligan a sus proveedores a actuar bajo este paraguas), ya que nos facilita un alto grado de trazabilidad en el proceso y nos permite captar en tiempo real datos que nos suministrarán información sobre el proveedor, su cliente, tiempos de entrega, recursividad en los pedidos, decrecimiento o incremento del volumen operacional del proveedor, cancelaciones de pedidos, discrepancias entre lo pedido y enviado, descuentos en el pedido, etc. (en definitiva, toda la información relevante que podríamos definir como endógena a las operaciones entre el proveedor y la gran marca a la que suministra) y apoyándonos en las nuevas tecnologías, para el análisis y tratamientos del Big Data, que nos aportará la información exógena a las operaciones que en particular lleven a cabo el proveedor y su cliente y que resultan de la misma importancia (por ejemplo, las tendencias que cada producto tienen en los mercados, variaciones estacionales de la demanda de un bien o la evolución de los precios y los descuentos en los grandes mercados).
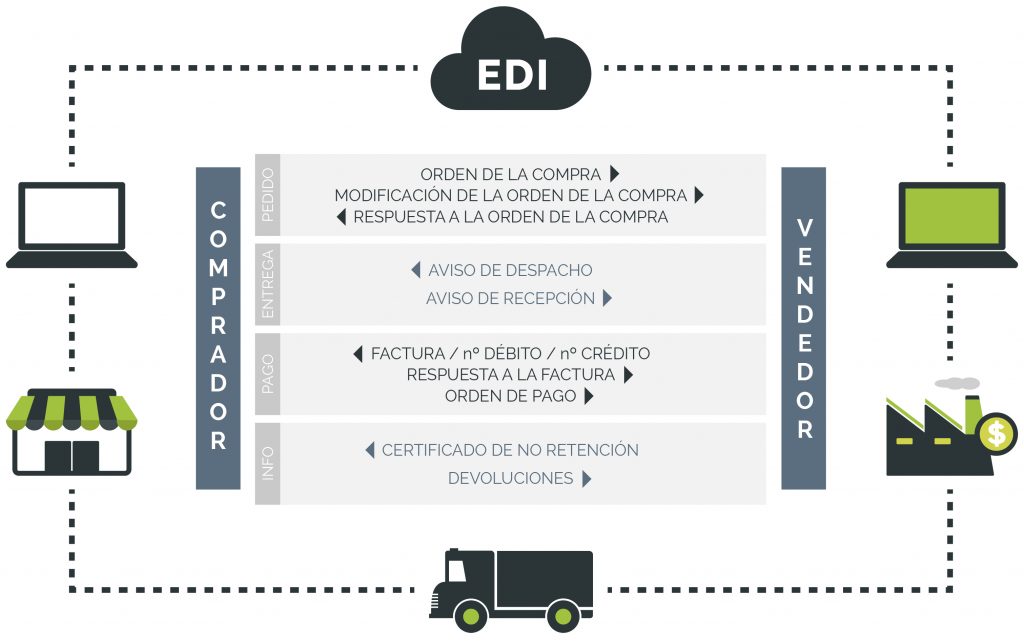
La idea innovadora que nos va a permitir ofrecer un producto, la financiación directa de órdenes de pedido para proveedores que abastecen a grandes marcas, con menor riesgo que las líneas de crédito actuales es que somos capaces de definir un scoring dinámico, que irá variando en cada nueva operación del proveedor con su cliente y fijará por tanto condiciones distintas en la financiación de cada operación (TAE, porcentaje de dinero respecto al total que figura en la orden de pedido dispuesto en la “cuenta scrow” según la consecución de los hitos que marcan la operación, etc.), basado en la correlación de las variables endógenas (definidas en base a la información que captamos a través de los archivos EDI que se generan en la relación comercial entre el proveedor y la gran superficie a la que suministra) y las variables exógenas (aquellas otras que son externas a la operación concreta entre el proveedor y su cliente, pero que al identificarse con las tendencias y evolución de los grandes mercados no se pueden obviar para confeccionar un análisis preciso de posibles riesgos, y que debido al volumen de datos que representan necesitan de herramientas para el procesamiento de la Big Data) con los eventos: “El proveedor no devuelve la financiación” y/o “El proveedor se retrasa en la devolución de la financiación”.
En resumen, vamos a ser proactivos para anticipar el riesgo mucho antes que los métodos tradicionales, a través de un sistema autónomo de aprendizaje que encuentre patrones de comportamiento analizando las bases de datos, entre una gran cantidad de premisas definidas en base a las variables (como por ejemplo el histórico de retrasos en las entregas del pedido, la cantidad de pedidos cancelados, el incremento del volumen operacional respecto al esperado por las tendencias de los mercados en un mes concreto, el precio de un producto que figura en el pedido respecto al esperado por la evolución de los precios en los mercados, si el proveedor hace descuentos mayores de los esperados, etc.) y la correlación con los eventos del párrafo anterior, dando lugar a un algoritmo que optimice la correlación de éstas. Una MACHINE LEARNING para calcular el scoring de riesgo en una determinada operación fijando por tanto unas condiciones distintas para financiar la misma.
Vamos a desarrollar un ejemplo que nos permitirá visualizar de forma más precisa el funcionamiento de nuestro sistema y algunas de las características que se tendrán en cuenta para predecir posibles escenarios de riesgo: consideremos un proveedor que lleva ya tiempo financiándose a través de Smart Scrow y suministra una media de 1,7 pedidos por semana de aceitunas a una gran superficie. Como aclaración previa, para iniciar la colaboración entre un proveedor y Smart Scrow se realizará un análisis para comprobar la solvencia de dicho proveedor (CIRBE, deudas con Hacienda o la Seguridad Social, contrato que formaliza su vinculación como proveedor de una gran marca, etc.). Si dicho análisis es satisfactorio, tendremos acceso vía EDI a las operaciones que ya ha llevado a cabo con su cliente, permitiéndonos calcular un pre-scoring de riesgo que será el punto de partida para la primera operación que va a financiar con nosotros.
Supongamos ese escenario superado. Nuestro proveedor de aceitunas lleva financiando sus órdenes de pedido 6 meses con nosotros, y por la media de pedidos semanales que comentamos anteriormente, en total hemos financiado 44 operaciones. Paulatinamente, conforme se han sucedido esas operaciones, nuestro sistema ha ido capturando información que nos permite conocer datos como el porcentaje de envíos que llegaron con retraso, envíos cancelados porque la mercancía llegó dañada, envíos cancelados porque cuando el producto llegó al almacén de su cliente la fecha de caducidad del mismo no tenía el margen requerido, cuántas veces se envió menos mercancía de la reflejada en la orden de pedido, cuántas veces se ha retrasado el proveedor en la devolución de la financiación, si se ha incrementado o no el volumen operacional del proveedor con la gran marca, evolución del precio del producto que factura este proveedor en concreto con su cliente, si cada vez realiza más descuentos a la gran marca y muchos más de este estilo. En definitiva, a través de los archivos que se generan en la comunicación vía EDI entre el proveedor y su cliente en cada operación, se generarán bases de datos con las variables que antes identificábamos como endógenas al propio proceso y que evidentemente aportan información estrechamente relacionada para poder predecir si un proveedor va a tener problemas para devolver la financiación que se va a generar en la orden de pedido 45 que nos acaba de llegar.
En esta orden de pedido, que supone la operación 45 que el proveedor va a financiar con nosotros, nos fijamos que la gran superficie pide un 10% más de cantidad de aceitunas de la cantidad media en los pedidos anteriores. En principio parece algo positivo ya que se incrementa el volumen. No obstante, en nuestras bases de datos, que son las que nos aportan la información externa (lo que identificábamos como información exógena) a la relación particular entre nuestro proveedor de aceitunas y su cliente, nos damos cuenta que en esta semana concreta del año, el incremento medio de cantidad de aceitunas que las grandes superficies compran es del 30% (debido a que se acerca la Semana Santa y las grandes superficies hacen aprovisionamiento de este producto en las semanas previas por el aumento de ventas en esta determinada época del año). Nuestra Machine Learning ha identificado que un incremento en ventas menor a lo esperado es un evento que está relacionado con el retraso en la devolución de la financiación. Por tanto, nuestro sistema bajará el scoring del proveedor, imponiendo unas condiciones más restrictivas para la financiación. Gracias al análisis de la Big Data, nuestro sistema es capaz de filtrar sucesos que a priori pueden parecer positivos pero realmente suponen una disminución del negocio, como ocurre exactamente en el ejemplo que nos ocupa, con anterioridad a que esto se refleje en las grandes cuentas de la empresa del proveedor.
De igual forma, actuaría si por ejemplo se detecta entre las variables endógenas que podemos definir gracias a la información que nos aportan los ficheros generados a través de la comunicación EDI, que habiéndose producido un incremento en la cantidad del producto requerido por la gran marca en la orden de pedido al proveedor, dicho incremento se debe a un aumento de los descuentos respecto a los esperados. En este caso, realmente se está produciendo una “devaluación” del producto que tiene que reflejarse en las condiciones de la financiación. Cuando se produce un aumento de los pedidos porque dicho producto esta «con precio», lo pedido de más va a almacén y el siguiente pedido se realizará más dilatado en el tiempo.
Es decir, a través del análisis estadístico y de Big Data de multitud de variables, tanto internas a una relación particular entre un proveedor y la gran marca a la que suministra y las que representan las tendencias en los grandes mercados, nuestra Machine Learning va identificar los patrones de correlación entre éstas y los posibles riesgos de una operación que puedan derivar en retrasos o impagos de la devolución de la financiación, anticipándonos al modelo más tradicional o clásico basado en el análisis de balances y cuentas trimestrales. De esta forma presentamos un producto innovador, apoyándonos en los avances tecnológicos y en las nuevas formas de tratamiento y análisis de la Big Data, que consigue llegar a las primeras fases del tejido productivo.
Artículo escrito por Oscar Contreras Mora, Ingeniero Matemático